UNQL
UNQL
UNQL is the Uninode® Query Language, for querying data sources using Uninode® and Edgescript®. Read More About Uninode® Suite
Structure
UNQL is a JSON/Edgescript® structure for server queries.
A query JSON structure looks like this;
{-
"edgeSpaces": [{ (optional, array is used for enforcing join order)
-
"<Edgespace code>": {
- "className": "<Class name>"
- "filter": "<Edgescript® filter>" (optional)
-
"<Edgespace code>": {
- "titlePath": <Edgepath> (optional)
- "paths": [<Edgepath, e.g. "\Asset.name" or "\.name">, ...]
- "orderPaths": [<Edgepath>, ...] (optional)
- "filters": ["<Edgescript® filter>", ...] (optional)
- "isDistinct": <true or false> (optional, default false)
- "limit": <number> (optional, default 100)
- "maxClassCount": <number> (optional, default 1)
-
"tree": { (optional, used for intra-level tree hierarchy)
- "path": <Edgepath> (optional, used if parent and child are stored in another table)
- "parent": <Edgepath>
- "child": <Edgepath>
-
"layers": [{ (optional, used for data layers)
- "path": <Edgepath> (optional, path to layer id)
- "parent": <Edgepath> (optional, path to layer parent id)
-
"levels": [{ (optional, used for tree level queries)
- "isHidden": <true or false> (optional, records for this level are marked with "isHidden": true)
-
"paths": [ (optional, used for connecting this level to next)
- "parent": <Edgepath>
- "child": <Edgepath>
- "query": [<query>, ...] (optional, query for next level)
A request JSON structure looks like this:
{- "lang": "<Language code>"
- "siteCode": "<Site code>"
- "packCode": "<Package code>"
- "orgCode": "<Organization code>"
- "appCode": "<App code>"
- "query": <query>
UNQL Response
Like the UNQL query, the UNQL reply has a JSON format, so it can be handled by clients other than specific UNQL clients.
One solution would be to let the reply mimic the instance structure of the classes, but that will not work for as hoc tree structures or scripts other than pure property access. Since there are no classes corresponding to results, the result cannot be type-checked.
The result must be able to handle circular references.
The response format does not have to be identical to other formats, like GraphQL, SparQL, Neo4j/Cypher or JSON-LD. Those are quite versbose.
Edgescript®
Edgescript®
UNQL uses the Edgescript® programming language for various dynamic behavior. Read more about Edgescript®
Edgespace
An edgepath is a reference to a property of some object. It normally requires a class name and a property name, e.g. \Asset.name.
A named edgespace can be used in an edgepath instead of the class name, e.g. \a.name, if a is the name of an edgespace. The default edgespace has no name, and the corresponding edgepath would look like \.name;
Note that two edgespaces in a query may have the same class. For instance, the default edgespace may have the class Asset, and the 'compare' edgespace may have the class Asset and the filter "\.id==\compare.id&\.date=='2022-10-01'". This would result in a database left join where the second Asset table would be a comparison to the same asset at the date '2022-10-01'.
Nodelab
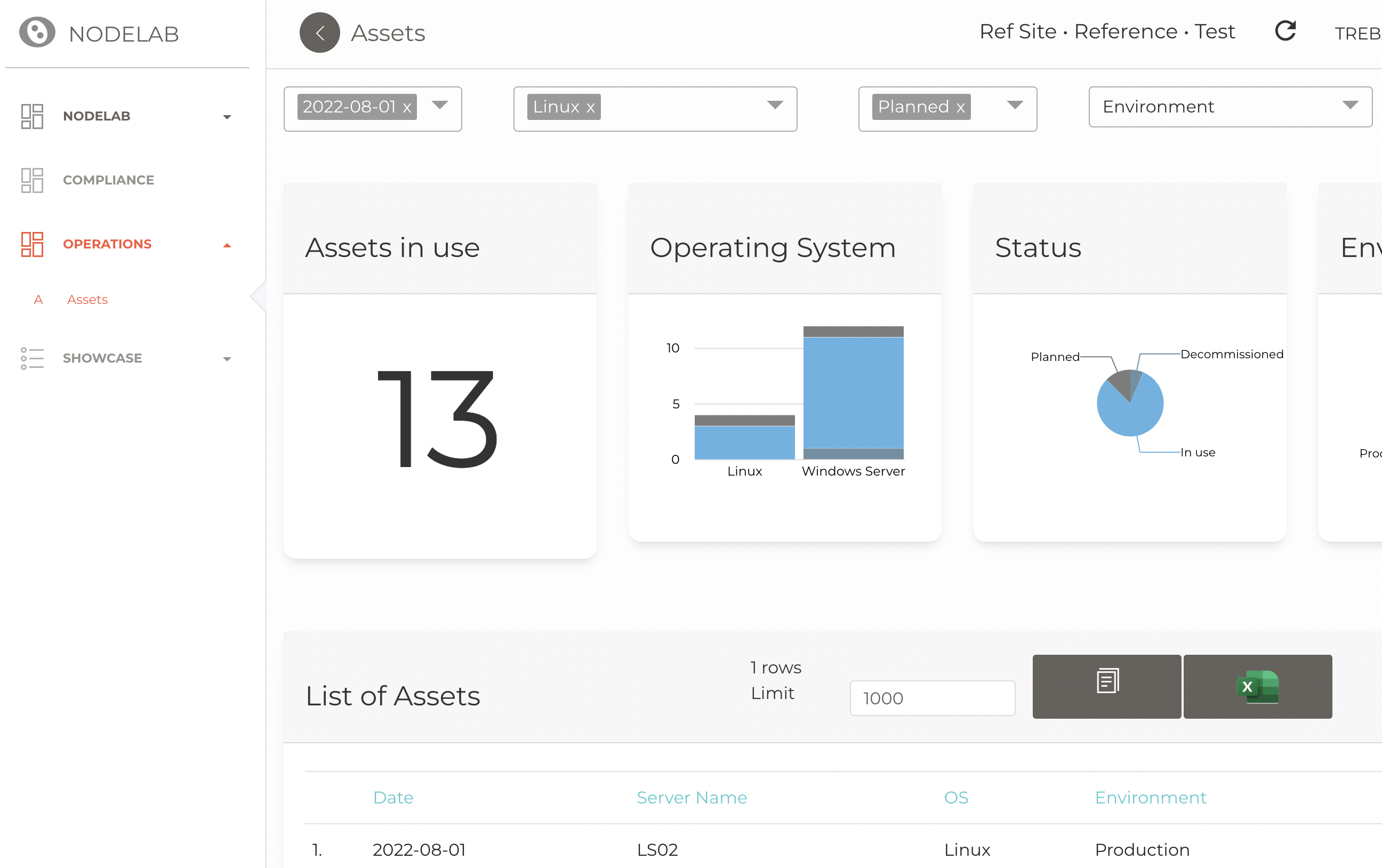
UNQL is used in the Nodelab product, for defining data models, processes and user interfaces. Read More
Query Phases
An UNQL query is parsed and executed in five progressively less abstract phases.
| Phase | Edgescript | |||
|---|---|---|---|---|
| Property | Function | Edgepath | Expression | |
| Parsing |
|
|||
| Resolution | Attributes are evaluated before other scripts are resolved, e.g. to adjust scope. | |||
|
|
|
Compiled evaluation trees from this phase may be cached and reused for identical scripts. | |
| Backend |
|
|||
| Backend properties may be cached based on data source, package and organization, but independent of script. | ||||
| Query |
|
|
|
|
| This result of this phase is not cached. | ||||
| Execution | Result is a row of maps, associating the script with its result. | |||
Records
Data Records
Data access is similar to a GIT repository.
- A deployment may have a number of repositories. It may have a main repository
- A repository may have a number of branches. One is the master branch.
- A branch may have a number of commits. One is the head commit.
- A commit may have a number of commit sources.
- A commit source associates a commit with a record source, and adds some meta data like validity span.
- A record source contains a set of records, e.g. an Excel file or realtime API access parameters.
- A record is associated with a Uniclass.
- A pattern defines how to parse a data feed into a set of records.